Raft Part I - Leader Election大选
Resource:
刚刚花了4天时间结束了Raft共识算法的第一个checkpoint,这里做一个总结。Raft 将会分为两个部分,在第一个部分中,我会通过go实现leader election并讲解核心测试设计。在美国2024大选之际,正好写一个民主选举的项目哈哈
核心思路
首先我们需要服务器的的3个状态: leader, follower, and candidate,在文章中:
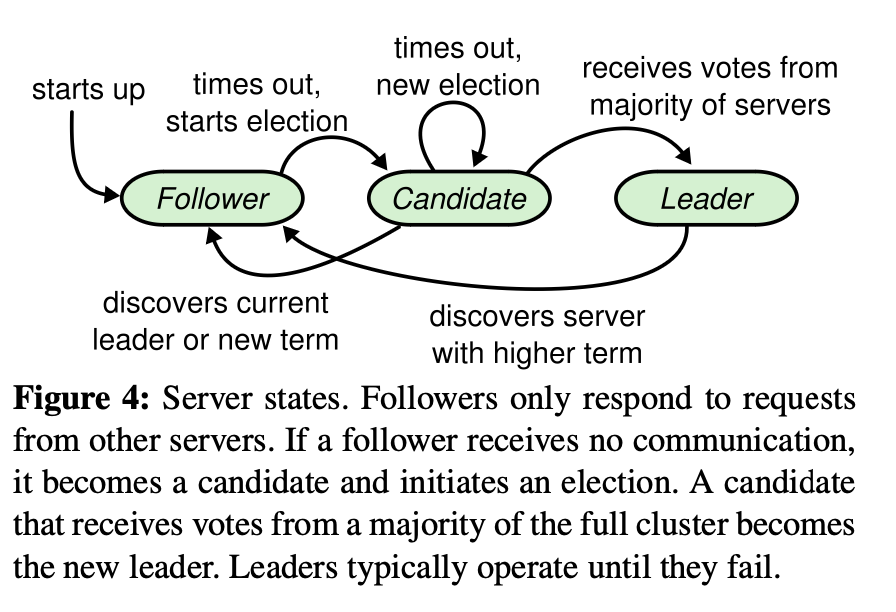
作为程序设计,我将这个部分更具体的表示成 run() 函数的几个通道接受信号后的表示:
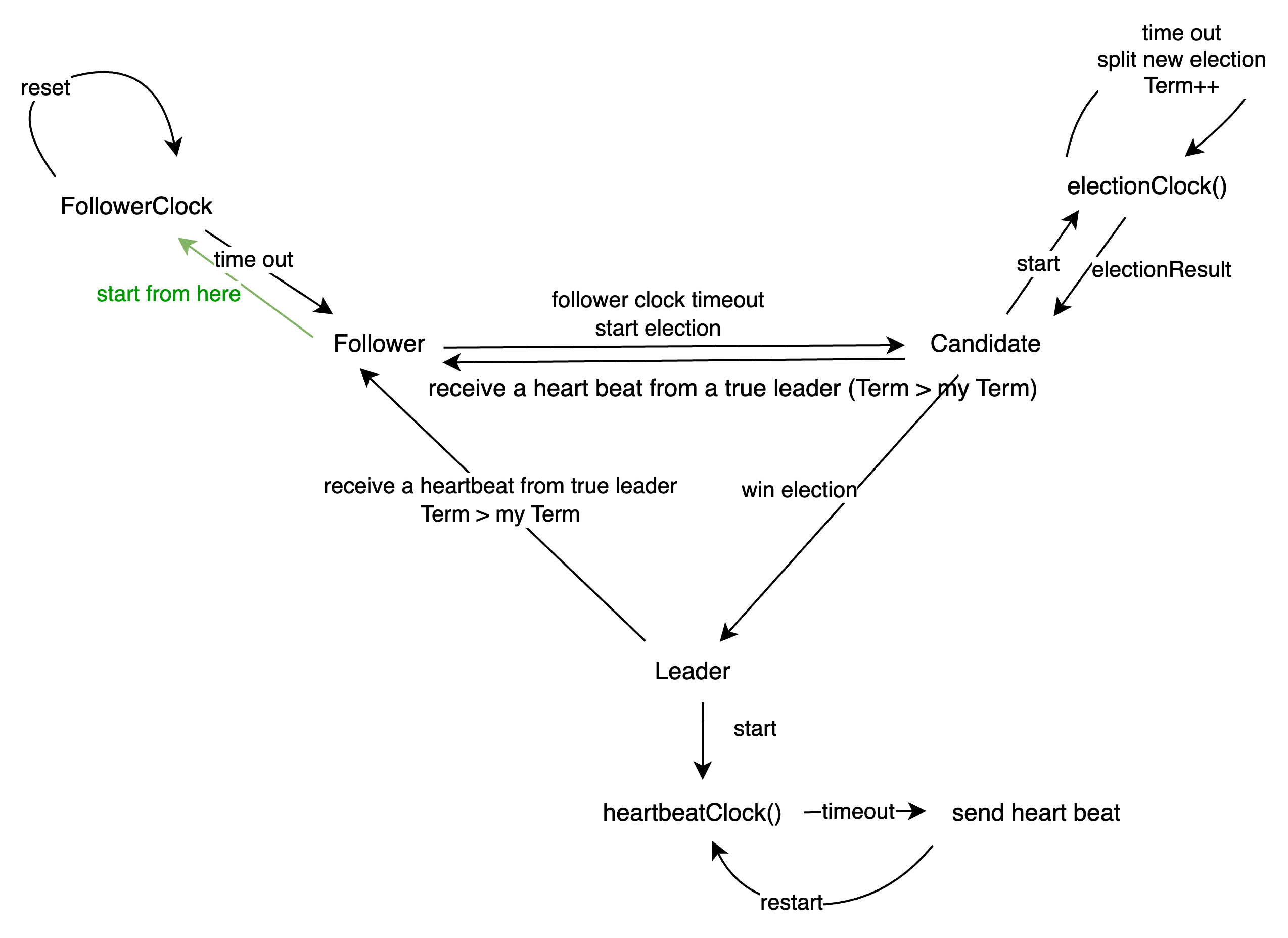
实现细节
run() 函数
run函数在初始化一个服务器的时候就会被go routine运行,此后,他一直作为一个中心接受各种输入。
- 如果接收到了
←rf.endRunCh的输入那么代表要结束这个go routine了,结束这个函数
- 如果接收到了
←rf.startLeaderCh的输入那么说明这个server从election中脱引而出,成为了新的leader,这时进行两个操作- 加锁后改变身份为leader,之后unlock
- 启动
go heartbeat()函数
- 如果接收到了leader server的心跳,也就是
←rf.heartbeatIn,需要分类讨论- 如果此时我是follower,
rf.resetFollowerClock <- struct{}{}使得follower clock重置random续命
- 如果我是Candidate,且我的Term小于等于heartbeat传入的Term,说明当前的这轮Term leader已经被选出,或者说我已经落后了几个Term版本了:
- 首先需要关闭election
- 之后降格成follower
- 跟上版本Term
- 如果我是Leader,且heartbeat 的Term大于我的Term,说明我是旧时代的leader,会被新时代淘汰,于是:
- 首先关闭heartbeat函数
- 之后降格成follower
- 跟上版本Term
- 如果此时我是follower,
followerClock()函数
它负责管理 Raft 节点在追随者(follower)状态下的计时器,用于检测leader的heartbeat。如果在指定的超时时间内没有收到heartbeat,节点将变异成Candidate,启动新的选举过程。
- 计时器初始化:函数开始时初始化一个计时器 timer,并确保在函数退出时停止计时器以释放资源。
- 超时设置:在每次循环中,计时器会被重置为一个随机的超时时间(1000到1500毫秒之间)。这种随机性有助于减少多个节点同时发起选举的可能性。
- closeFollowerClock:如果从该通道接收到信号,函数将退出。
- 计时器超时:如果计时器超时,意味着在指定时间内没有收到leader的heartbeat,节点将通过 startNewElectionCh 通道发起新的选举。
- resetFollowerClock:如果从该通道接收到信号,计时器将被重置。这通常表示节点收到了领导者的心跳信号,继续保持follower状态。
election()函数
启动election函数之后:
- identity变成Candidate
- currentTerm++, 版本更新
- voteFor = me,为自己投票
启动三个函数
go rf.electionClock(stopElectionClockCh)
go rf.elecParallelSend(stopElecParallelSend)
go rf.electionRecv(stopElectionRecv)之后接受信号:
- 如果<-rf.electionTimeoutCh,说明我在选举中没有得到大多数的票,此时我也不知道有没有选出真的leader,所以我要重新开始新一轮的选举
rf.startNewElectionCh <- struct{}{}
- 如果<-rf.closeElectionCh,说明通过run()函数中转信号,我已经知道新的leader已经选出了,我可以不用在竞选了,需要关闭这个election
- 我通过defer来回收
defer func() { close(stopElectionClockCh) close(stopElecParallelSend) close(stopElectionRecv) // drain the voteIn channel for len(rf.voteIn) > 0 { <-rf.voteIn } // fmt.Printf("\033[33m[Term:%d](%d) election done\033[0m\n", rf.state.currentTerm, rf.me) }()
- 我通过defer来回收
- 如果我收取到了election结果electionResult := <-rf.voteCollectCh:
- 如果获胜:
rf.startLeaderCh <- struct{}{}开启leader模式
- 如果
electionResult == splitVote,开启新的electionrf.startNewElectionCh <- struct{}{}
- 如果获胜:
elecParallelSend() electionRecv()函数
在文章中提到发送voteRequest的时候需要parallel,这里我们保证concurrent的,逻辑上来说就是对的,所以使用
go rf.sendRequestVote(i, &RequestVoteArgs{
Term: curTerm,
CandidateId: rf.me,
LastLogIndex: logLen - 1,
LastLogTerm: curTerm,
}, reply)发送RPC就可以,记得在访问state变量的时候加锁,不然可以会panic其他正在对state改变的操作
在RPC返回的时候我们就会需要立刻返回这个,所以我们构造一个buffer chan来回收每个选民的vote结果
if ok && reply.VoteGranted {rf.voteIn <- true}随后我们在electionRecv()函数中回收vote := <-rf.voteIn
electionClock()函数
electionClock比起follower clock更加简单,只需要检测是倒计时先结束还是外部把这个go routine先结束就行
RequestVote()
非常重要!!!这个是RPC的handler函数,所以他的正确实现关乎到了整个选举是否可以顺利。首先在整个函数的首尾整个加锁解锁保证在函数投票的时候前后的状态一致。总共有三种情况:
args.Term > rf.state.currentTerm- 投票
reply.VoteGranted = true
- 更新Term:
rf.state.currentTerm = args.Term
- 记录这轮把票投给了
rf.state.votedFor = args.CandidateId
- 此时还需分类讨论:
- 如果我是Candidate
- 变成 Follower,开始倒计时
rf.followerClock()
- 停止选举
rf.closeElectionCh <- struct{}{}
- 变成 Follower,开始倒计时
- 如果我是Leader
- 变成Follower,开始倒计时
rf.followerClock()
- 停止heartbeat行为
rf.closeHeartbeatClock <- struct{}{}
- 变成Follower,开始倒计时
- 如果我是Follower
- 重置倒计时
rf.resetFollowerClock <- struct{}{}
- 重置倒计时
- 如果我是Candidate
- 投票
args.Term == rf.state.currentTerm- 直接不投票就得了,为什么?如果我是follwer也不投票吗?是的,因为如果他是这一轮的leader那么他就应该发你heartbeat而不是发你vote request。他和你一个Term却在选举?他要是合理的选举必须比你大一个term至少!
args.Term < rf.state.currentTerm- 不给他投票且告知他
reply.Term = rf.state.currentTerm他已经落后一个term了
- 不给他投票且告知他
heartbeat(), sendHeartbeat()函数
很简单,倒计时到了就重新倒计时并使用一个go routine来go sendHeartbeat()
sendHeartbeat() 很简单对所有server RCPgo sendAppendEntries()
AppendEntries()函数
很重要!!!和RequestVote类似可以分三类
在开始前加锁,在结束前解锁
args.Term < rf.state.currentTerm- 失败的heartbeat
reply.Success = false
- 失败的heartbeat
args.Term == rf.state.currentTerm- 如果是follwer:
reply.Success = true
- 如果不是:
reply.Success = false
- 如果是follwer:
args.Term > rf.state.currentTermreply.Success = true
将heartbeatTerm发送到 run 中,进一步处理。 rf.heartbeatIn <- args.Term
测试设计
TestInitialElection2A
- 目的:验证在初始情况下,系统能否正确选举出一个领导者。
- 过程:创建3个服务器的集群,检查是否有一个领导者被选举出来。
TestReElection2A
- 目的:验证当现有领导者断开连接时,系统能否选举出新的领导者。
- 过程:在3个服务器的集群中,断开当前领导者的连接,然后检查是否选举出新的领导者。
TestReElectionHidden2A
- 目的:测试在网络故障后,系统能否正确进行重新选举。
- 过程:在5个服务器的集群中,断开当前领导者并选举新的领导者,然后模拟网络分区,断开多个节点,检查没有领导者的情况,最后恢复连接并检查是否选举出新的领导者。
TestSmallPartitionConsensusHidden2A
- 目的:测试在网络分区情况下,系统能否在大多数分区中选举出新的领导者,并保持小分区的旧领导者。
- 过程:在5个服务器的集群中,创建一个包含领导者和一个追随者的小分区,以及一个包含大多数追随者的大分区,检查大分区中是否选举出新的领导者,并验证小分区中旧领导者是否仍然是领导者。
TestLeaderConsistencyHidden2A
- 目的:验证在重新选举后,系统能否保持领导者的一致性。
- 过程:在3个服务器的集群中,断开当前领导者并选举新的领导者,重新连接旧领导者,断开新的领导者和另一个节点,检查是否能选举出新的领导者。